Resiliency
Distributed applications are commonly comprised of many microservices, with dozens - sometimes hundreds - of instances scaling across underlying infrastructure. As these distributed solutions grow in size and complexity, the potential for system failures inevitably increases. Service instances can fail or become unresponsive due to any number of issues, including hardware failures, unexpected throughput, or application lifecycle events, such as scaling out and application restarts. Designing and implementing a self-healing solution with the ability to detect, mitigate, and respond to failure is critical.
Resiliency Policies
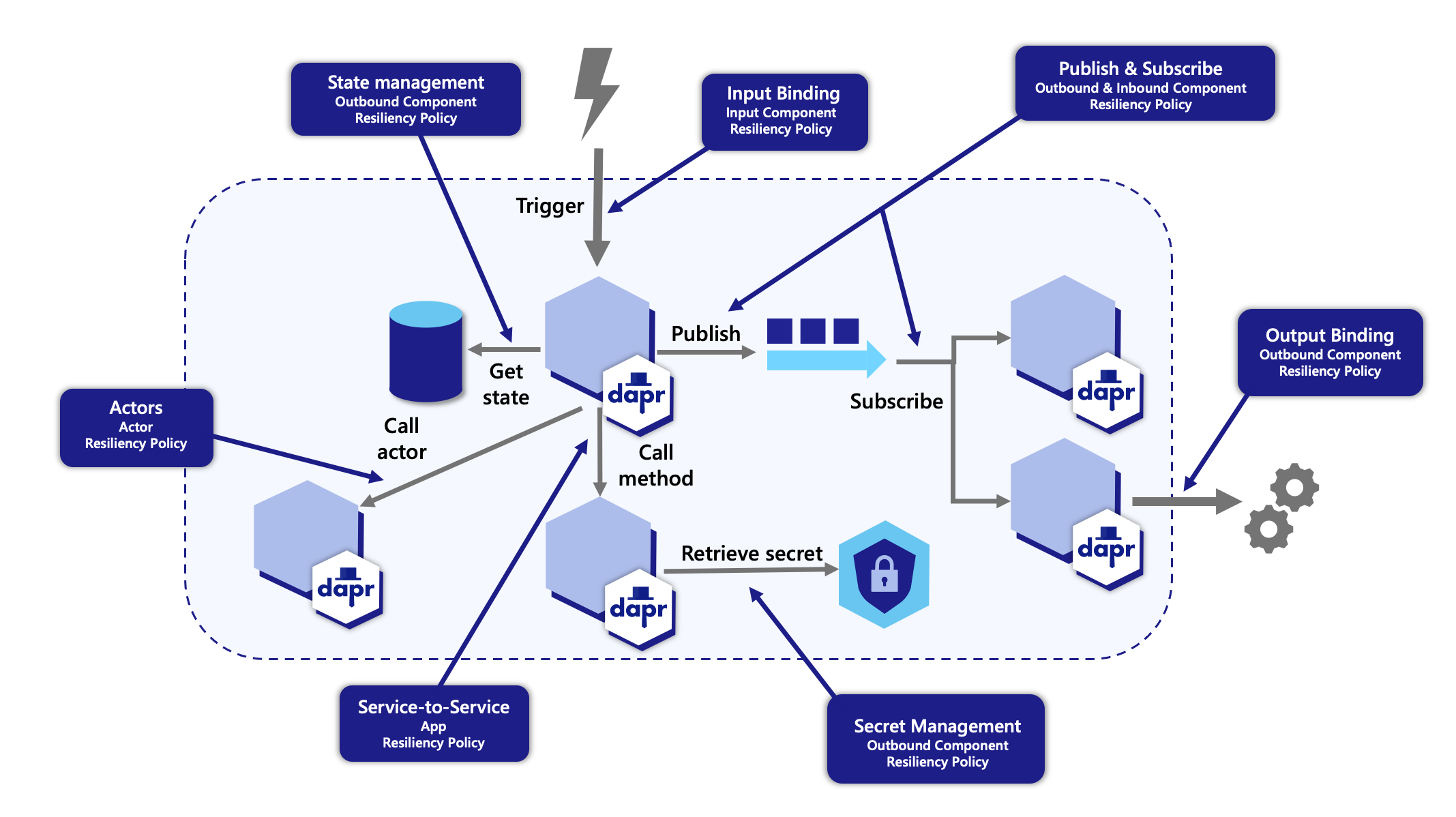
Dapr provides a capability for defining and applying fault tolerance resiliency policies to your application. You can define policies for following resiliency patterns:
- Timeouts
- Retries/back-offs
- Circuit breakers
These policies can be applied to any Dapr API calls when calling components with a resiliency spec.
App Health Checks

Applications can become unresponsive for a variety of reasons. For example, they are too busy to accept new work, could have crashed, or be in a deadlock state. Sometimes the condition can be transitory or persistent.
Dapr provides a capability for monitoring app health through probes that check the health of your application and react to status changes. When an unhealthy app is detected, Dapr stops accepting new work on behalf of the application.
Read more on how to apply app health checks to your application.
Sidecar Health Checks

Dapr provides a way to determine its health using an HTTP /healthz endpoint. With this endpoint, the daprd process, or sidecar, can be:
- Probed for its health
- Determined for readiness and liveness
Read more on about how to apply dapr health checks to your application.
Next steps
- Learn more about resiliency
- Try out one of the Resiliency quickstarts:
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.